Chapter 4: Content Processing and Storage
In this chapter, we'll dive into how to process the collected content and prepare it for vector storage. We'll cover HTML content extraction, markdown conversion, text preprocessing, and efficient storage strategies.
💡 Get the Complete n8n Blueprints
Fast-track your implementation with our complete n8n blueprints, including the content processing workflow covered in this chapter. These production-ready blueprints will save you hours of setup time.
Here's how the n8n workflow will look like at the end:
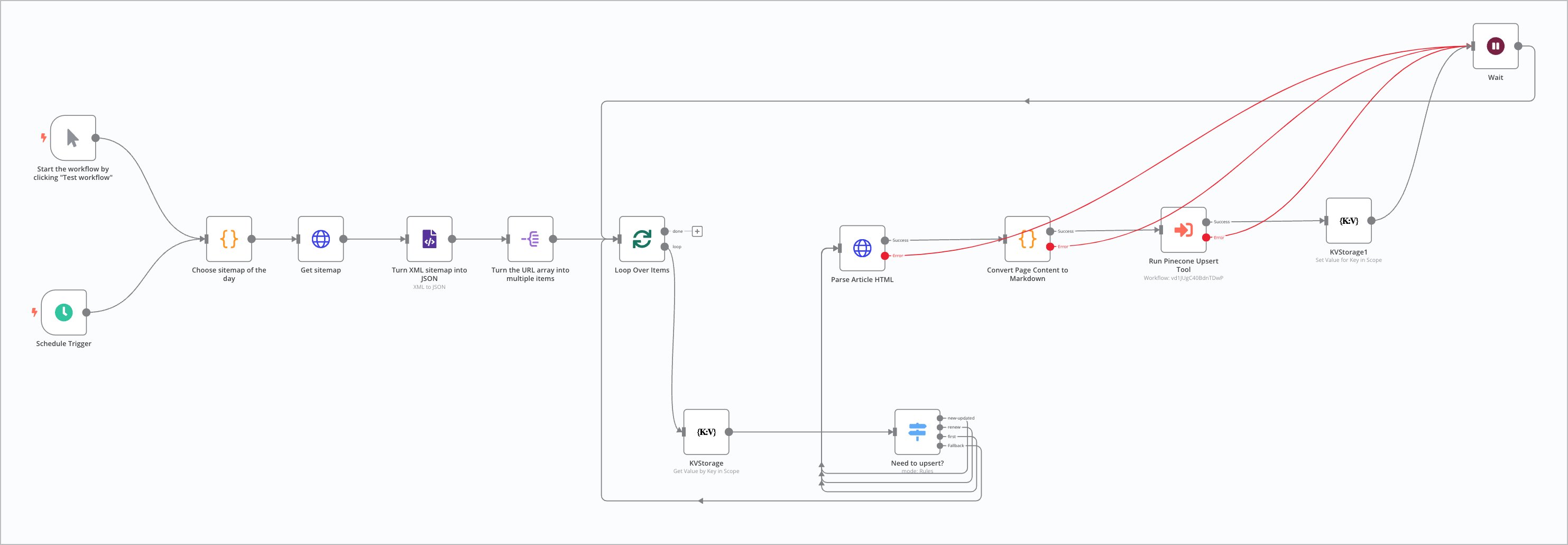
HTML Content Extraction
Setting Up the HTTP Request Node
The first step is to fetch the HTML content from each URL:
{
"parameters": {
"url": "={{ $node[\"Loop Over Items\"].json[\"loc\"] }}",
"sendHeaders": true,
"specifyHeaders": "json",
"jsonHeaders": {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
}
}
Error Handling and Retries
Implement robust error handling:
{
"retryOnFail": true,
"maxTries": 5,
"waitBetweenTries": 5000,
"onError": "continueErrorOutput"
}
Converting Content to Markdown
Setting Up the Content Conversion Node
We use a combination of JSDOM and Turndown for HTML to Markdown conversion:
// Import required modules
const { JSDOM } = require('jsdom');
const TurndownService = require('turndown');
// Initialize Turndown service
const turndownService = new TurndownService();
// Process HTML content
const processContent = (htmlContent) => {
// Create virtual DOM
const dom = new JSDOM(htmlContent);
const document = dom.window.document;
// Clean unwanted elements
const unwantedTags = [
'script', 'style', 'nav', 'footer',
'header', 'aside', 'ads'
];
unwantedTags.forEach(tag => {
document.querySelectorAll(tag).forEach(el => el.remove());
});
// Convert to Markdown
return turndownService.turndown(document.body.innerHTML);
};
Content Cleaning and Preprocessing
Implement content cleaning functions:
function cleanContent(markdown) {
return markdown
// Remove excessive newlines
.replace(/\n{3,}/g, '\n\n')
// Remove HTML comments
.replace(/<!--[\s\S]*?-->/g, '')
// Normalize whitespace
.replace(/\s+/g, ' ')
// Clean up markdown artifacts
.replace(/\[\s*\]/g, '')
.trim();
}
Text Cleaning and Preprocessing
Content Normalization
function normalizeContent(text) {
return text
// Convert to lowercase
.toLowerCase()
// Remove special characters
.replace(/[^\w\s-]/g, '')
// Replace multiple spaces
.replace(/\s+/g, ' ')
// Trim whitespace
.trim();
}
Content Length Management
Large documents need to be split into manageable chunks while maintaining data integrity and relationships. Here's how we implement this:
// Function to split markdown content into chunks of specified size
function splitMarkdown(markdown, maxLength = 20000) {
let chunks = [];
let currentIndex = 0;
while (currentIndex < markdown.length) {
// Find the last period before maxLength to avoid splitting sentences
let endIndex = currentIndex + maxLength;
if (endIndex < markdown.length) {
// Look for the last period within the last 1000 characters of the chunk
const searchRange = markdown.substring(endIndex - 1000, endIndex);
const lastPeriodIndex = searchRange.lastIndexOf('.');
if (lastPeriodIndex !== -1) {
// Adjust endIndex to end at the period
endIndex = endIndex - (1000 - lastPeriodIndex);
}
} else {
endIndex = markdown.length;
}
// Extract the chunk
const chunk = markdown.substring(currentIndex, endIndex);
chunks.push(chunk);
// Move to next chunk
currentIndex = endIndex;
}
return chunks;
}
// Process each item and handle content splitting
const processContentChunks = (items) => {
const processedItems = [];
items.forEach(item => {
const markdown = item.json.data.markdown;
// If markdown is longer than maxLength, split it
if (markdown.length > 20000) {
const chunks = splitMarkdown(markdown);
// Create new items for each chunk
chunks.forEach((chunk, index) => {
processedItems.push({
json: {
indexName: item.json.indexName,
namespace: item.json.namespace,
data: {
markdown: chunk,
url: item.json.data.url,
title: item.json.data.title
},
// Keep original ID for first chunk, add index for others
id: index === 0 ? item.json.id : `${item.json.id}-${index}`
}
});
});
} else {
// If markdown is within length limit, keep original item
processedItems.push(item);
}
});
return processedItems;
};
This implementation provides several key benefits:
Intelligent Splitting
- Splits content at sentence boundaries to maintain readability
- Preserves document structure and metadata
- Ensures no content is lost during splitting
ID Management
- Maintains original ID for the first chunk
- Creates sequential IDs for additional chunks (-1, -2, etc.)
- Ensures unique identification while preserving origin
Length Control
- Maintains chunks under 20,000 characters
- Optimizes for vector storage limits
- Improves processing efficiency
Data Integrity
- Preserves all metadata and references
- Maintains URL and title information
- Keeps indexing and namespace consistency
Example of split document IDs:
Original: https://bizstack.tech/entrepreneur-spotlight
Chunk 1: https://bizstack.tech/entrepreneur-spotlight (original ID)
Chunk 2: https://bizstack.tech/entrepreneur-spotlight-1
Chunk 3: https://bizstack.tech/entrepreneur-spotlight-2
Metadata Extraction
Extract and structure metadata:
function extractMetadata(document) {
return {
title: document.title,
description: document.querySelector('meta[name="description"]')?.content,
keywords: document.querySelector('meta[name="keywords"]')?.content,
lastModified: document.querySelector('meta[property="article:modified_time"]')?.content,
author: document.querySelector('meta[name="author"]')?.content,
url: cleanUrl(pageUrl)
};
}
Implementing the Pinecone Upsert Tool
Workflow Structure
The Pinecone upsert tool consists of three main components:
- Document Processing
- Embedding Generation
- Vector Storage
Document Processing
async function processToPinecone({
inputData,
embeddingsInput,
pineconeApiKey,
indexName,
namespace,
}) {
// Document preparation
const docs = inputData.map(item => {
const { data, id } = item.json;
// Combine text content
let textContent = [];
for (const [key, value] of Object.entries(data)) {
if (typeof value === 'string') {
textContent.push(`${key}: ${value}`);
}
}
return {
pageContent: textContent.join('\n'),
metadata: {
source: id,
...data,
original_structure: Object.keys(data).join(',')
},
id: id
};
});
return docs;
}
Text Chunking Strategy
Implement efficient text chunking:
const { RecursiveCharacterTextSplitter } = require("langchain/text_splitter");
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 0,
});
// Process and split documents
const processedDocs = [];
for (const doc of docs) {
if (typeof doc.pageContent === 'string' && doc.pageContent.trim()) {
const cleanContent = doc.pageContent
.replace(/\s+/g, ' ')
.trim();
const fragments = await splitter.createDocuments([cleanContent]);
processedDocs.push(...fragments.map((fragment, idx) => ({
...fragment,
metadata: {
...fragment.metadata,
...doc.metadata,
chunk_index: idx,
total_chunks: fragments.length
},
id: `${doc.id}|${idx}`
})));
}
}
Vector Storage Management
Pinecone Configuration
Set up the vector store:
const { PineconeStore } = require('@langchain/pinecone');
const { Pinecone } = require('@pinecone-database/pinecone');
const pinecone = new Pinecone({
apiKey: pineconeApiKey
});
const pineconeIndex = pinecone.Index(indexName);
const vectorStore = new PineconeStore(embeddingsInput, {
namespace: namespace || undefined,
pineconeIndex,
});
Efficient Upsert Strategy
Implement batch upserts:
// Define IDs for upsert
const ids = processedDocs.map(doc => `${doc.id}`);
await vectorStore.addDocuments(processedDocs, ids);
Performance Optimization
Memory Management
Implement efficient memory handling:
function optimizeMemoryUsage(docs) {
// Process in chunks to manage memory
const chunkSize = 100;
const chunks = [];
for (let i = 0; i < docs.length; i += chunkSize) {
chunks.push(docs.slice(i, i + chunkSize));
}
return chunks;
}
Processing Speed Optimization
async function processChunksInParallel(chunks) {
const results = await Promise.all(
chunks.map(async chunk => {
return await processChunk(chunk);
})
);
return results.flat();
}
Best Practices and Tips
Content Quality
- Remove boilerplate content
- Maintain semantic structure
- Preserve important metadata
Storage Efficiency
- Implement deduplication
- Use appropriate chunk sizes
- Maintain proper indexing
Error Handling
- Implement retry mechanisms
- Log processing errors
- Monitor storage operations
Next Steps
With content processing and storage implemented, we're ready to move on to vector storage and retrieval in the next chapter. We'll cover:
- Advanced vector search
- Relevance optimization
- Query processing
- Response generation
Key Takeaways:
- Efficient content extraction
- Robust preprocessing
- Optimized storage strategy
- Performance considerations
Next Chapter: Vector Storage and Retrieval